| Oracle 19c 数据库使用的基本知识 | 您所在的位置:网站首页 › oracle 19c ojdbc版本 › Oracle 19c 数据库使用的基本知识 |
Oracle 19c 数据库使用的基本知识
|
Oracle 数据库的安装和卸载
一、安装
链接:Oracle 下载 二、卸载执行deinstall.xml 文件进行自动卸载操作,执行过程中输入回车或者yes,不能删除的目录在卸载执行完成后手动删除。 sys 要拥有系统管理员权限 system 可以直接登录 sysman 用来操作企业管理器,管理员级别 scott Oracle 创始人名字,默认密码是tiger 登录 使用system 用户登录 [username/password] [@server] [as sysdba|sysper]
管理员数据字典:dba_tablespaces、dba_users 普通用户数据字典:user_tablespaces、user_users
设置联机或脱机状态:ALTER TABLESPACE tablespace_name ONLINE|OFFLINE; 设置只读或可读写状态:ALTER TABLESPACE tablespace_name READ ONLY|READ WRITE; 表空间修改数据文件增加数据文件:ALTER TABLESPACE tablespace_nama ADD DATAFILE 'xx.dbf' SIZE xx; 删除数据文件:ALTER TABLESPACE tablespace_nama DROP DATAFILE 'xx.dbf'; (不能删除第一个数据文件,除非把表空间删掉) 删除表空间 DROP TABLESPACE tablespace_name [INCLUDING CONTENTS] 五、数据类型 字符型CHAR(n): MAX-2000 NCHAR(n): MAX-1000, unicode格式,存储汉字比较多 VARCHAR2(n): MAX-4000 NVARCHAR2(n): MAX-2000, unicode格式 数值型NUMBER(p,s) : p-有效数字位数,s-保留小数位数 FLOAT(n) : 二进制数据 1~126位 (*0.30103 得到10进制数据) 日期型DATE: 精确到秒 TIMESTAMP: 精确到毫秒 其他类型 大文件BLOB: 4G 二进制 CLOB: 4G 字符串 六、管理表 创建表
比delete速度快,删除全部数据,不删除表结构。 TRUNCATE TABLE table_name;删除表结构 DROP TABLE table_name; 在创建时复制表 CREATE TABLE new_table AS SELECT column1,...|* FROM old_table; 在添加时复制表 INSERT INTO new_table [(column1,...)] SELECT column1,...|* FROM old_table; 七、约束 :定义规则和确保完整性非空约束:数据不能是NULL值,如用户名、密码等(设置非空约束之前表中不能有空数据) 主键约束:唯一标识,不能为空,加快查询速度,自动创建索引。一张表只能设计一个,可以由多个字段构成(联合或复合主键)。 删除当前约束 ALTER TABLE table_name DROP CONSTRAINT constraint_name; DROP PRIMARY KEY [CASCADE] ; [CASCADE] :外键约束关系外键约束:主表的字段必须是主键,主从表中响应的字段是同一个数据类型,从表外键字段值必须来自主表中相应字段值,或者为null值。 创建表时添加外键约束 CREATE TABLE table2 (column_name datatype REFERENCES table1(column_name));
唯一约束:字段值不能重复 唯一约束和主键约束的区别 主键必须是非空,唯一约束允许有一个空值。主键在每张表中只能有一个,唯一约束在每张表中可以有多个。 检查约束:使表当中的值具有实际意义。
更改字符长度(字符类型)
函数的作用 方便数据统计处理查询结果函数的分类 数值函数四舍五入: ROUND(n,[,m]) ; 省略m : m = 0 取整; m>0 : 保留小数点后m位;m>字符:TO_CHAR(date[,format[,params]]) date:将要转换的日期 ; format:转换的格式; params: 日期的语言,通常不写;
联合索引比单索引的效率高么? 如果联合索引中的多个字段都在where谓词中出现了,则联合索引效率比单列索引高。因为通过多个条件可以从索引中过滤得到更少的记录条数,也就减少了需要回表扫描的次数,甚至可以直接在联合索引中得到所查的所有结果,则不再需要回表。 但是由于多列的联合索引肯定要比单列索引大,也就是说同样的索引需要存储的物理块要多于单列索引,所以,如果查询中只出现了联合索引中的某一列,则其效率不如单列索引。 前导列的作用? 前导列的概念是这样的,如果建立了f1,f2上的联合索引,则在查询时必须要用到f1,也就是所谓的前导列,该索引才会有效,因为索引是按照前导列排序的,如果where条件谓词中没有前导列,则需要执行索引扫描才能得到想要的结果,这种情况下其效率往往较差。 如果不需要前导列的话,reverse 这个反转又起到什么作用呢? 鉴于前面描述的前导列的概念,我们考虑如下表存储table(f1,f2); aa 1 ab 2 ac 3 ad 4 ae 5 如果我们对表table建立f1上的普通索引,由于按照f1进行排序,所以针对where f1=ad则需要遍历所有的a开始的索引,而如果对f1建立reverse索引,则由于da只有一个,则可以更快的得到需要的结果。 索引和前导列原文链接:https://blog.csdn.net/haoyuan2012/article/details/84745111 |
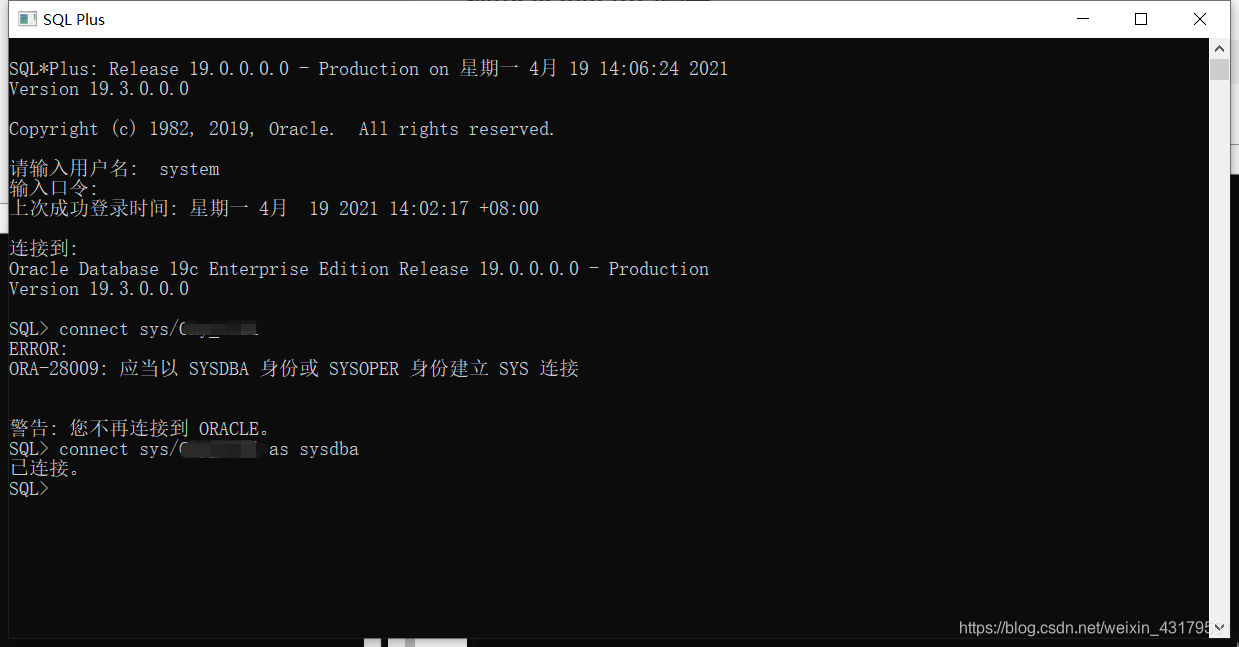 注意: 如果登录本地数据库就不用 @server 了
注意: 如果登录本地数据库就不用 @server 了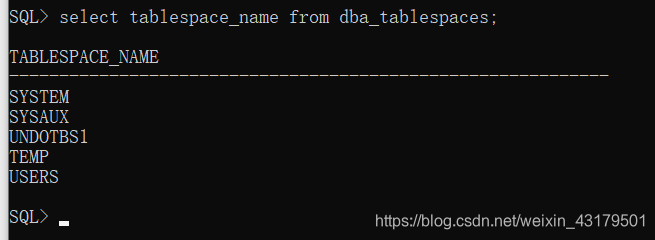
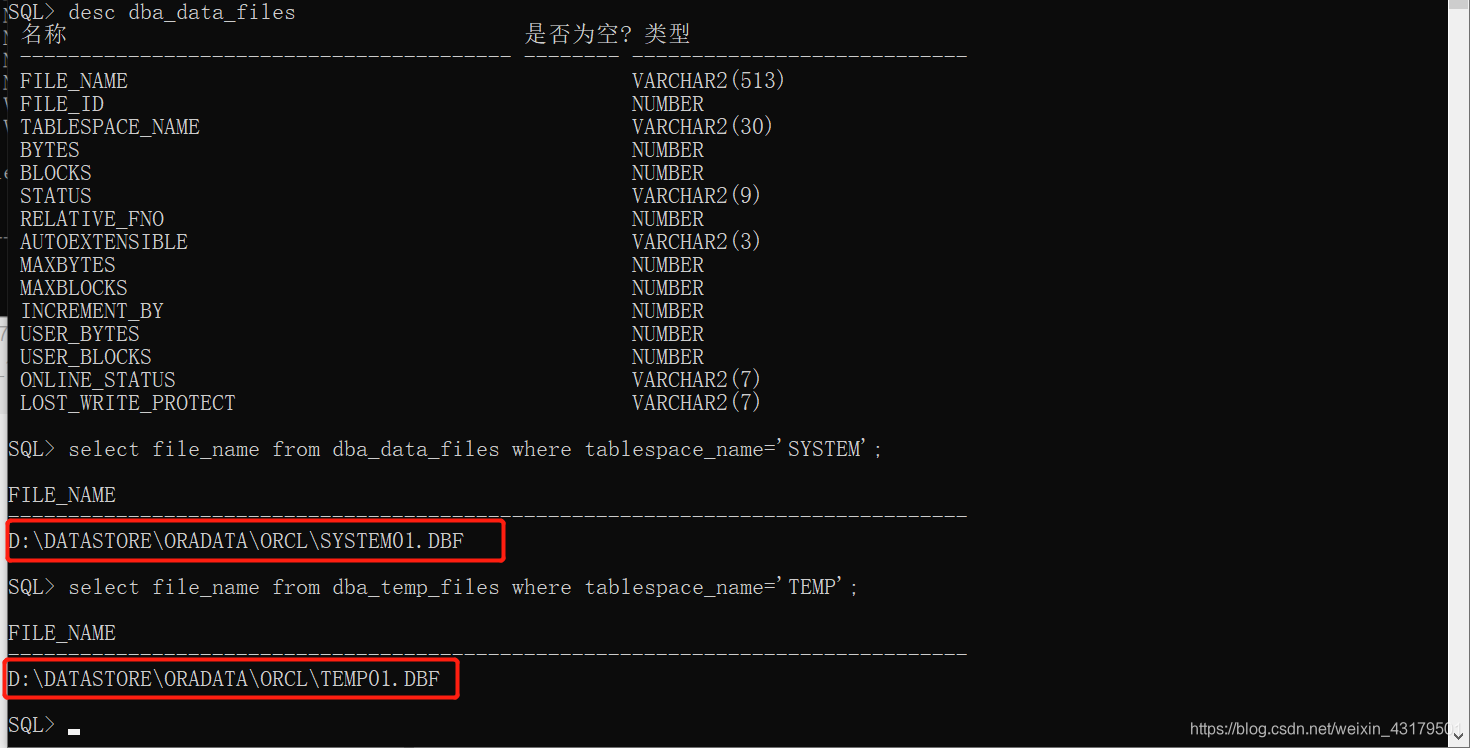



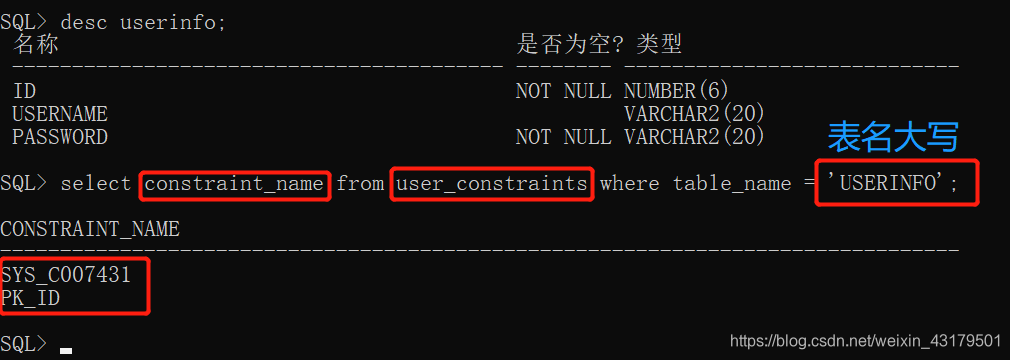
 启用|禁用当前约束
启用|禁用当前约束
 修改表时添加外键约束
修改表时添加外键约束




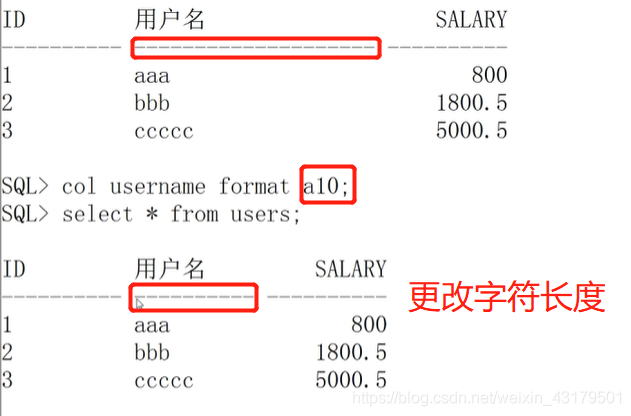 == 数值类型格式(“9”代表一个数字)==
== 数值类型格式(“9”代表一个数字)==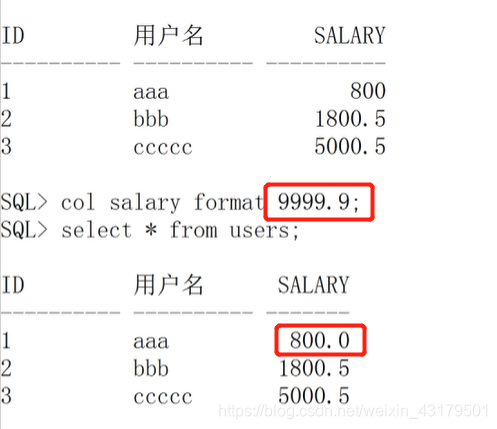
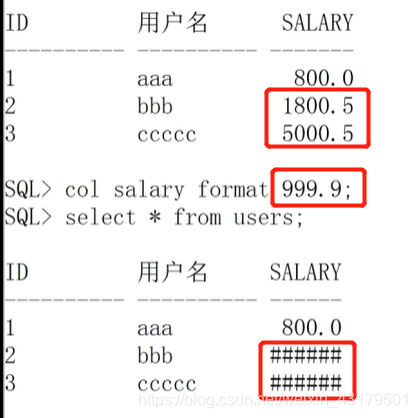
 == 清除设置的格式==
== 清除设置的格式== 字符>>日期:TO_DATE(date[,format[,params]]) --------只能输出默认日期格式 数字>>字符:TO_CHAR(number[,format]) 9: 显示数字并忽略前面的0 0:显示数字,位数不足,用0补齐 . 或D 显示小数点 , 或G 显示千位符 $:美元符号 S:加正负号(前后都可以)
字符>>日期:TO_DATE(date[,format[,params]]) --------只能输出默认日期格式 数字>>字符:TO_CHAR(number[,format]) 9: 显示数字并忽略前面的0 0:显示数字,位数不足,用0补齐 . 或D 显示小数点 , 或G 显示千位符 $:美元符号 S:加正负号(前后都可以) 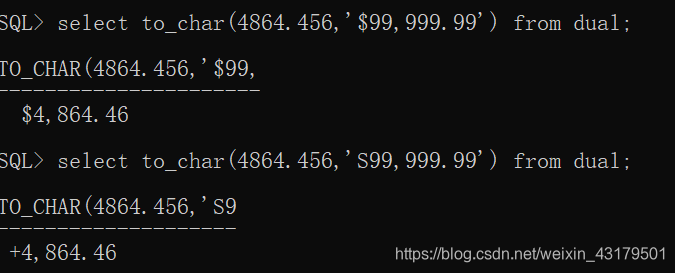 字符>>数字:TO_NUMBER(char[,format])
字符>>数字:TO_NUMBER(char[,format]) 

【本文地址】